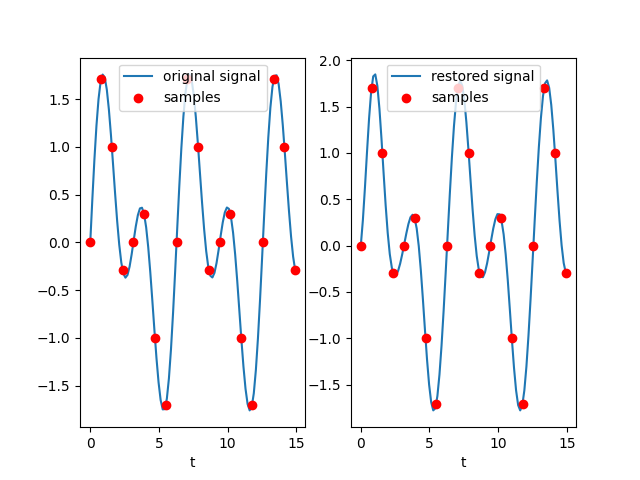
本文的主要目的是学习和研究如何制作一个面向移动端的、高效的深度学习推理引擎,面向有一定深度学习基础知识的用户。
一、ARM基础
1.开发工具与平台
本文主要针对ARMv7-A架构,编译工具链为NDK19,使用VSCode进行开发,主要语言为C和ARM,测试设备为小米10。
2.Hello,ARM!
1 | .text |
1 | export AS=$NDK_ROOT/toolchains/arm-linux-androideabi-4.9/prebuilt/linux-x86_64/bin/arm-linux-androideabi-as |